-
728x90반응형
11.1. RAID왜 사용되나
하드디스크의 장애로 인한 데이터 손실을 방지하기 위해 사용한다. 하드디스크는 사실 상 소모품으로 분류되며 I/O가 많은 서버에는 고장이 잦은 것이 당연하다고 볼 수 있다. 하지만 서버에 저장되는 데이터의 경우 손실 또는 유출 되었을 때 치명적일 수 있다 (ex 은행, 금융, 군사적 목적의 데이터를 관리하는 곳의 경우) 이로 인해 백업이 절대적으로 필요한 경우가 있고 또한, 여분의 디스크가 있어 용량을 증설하려고 할 때 데이터 손실 없이 증설이 필요한 경우가 있다. 그래서 많은 서버 관리자는 RAID 구성을 통해 하드디스크의 가용성을 높이거나 서버 데이터의 안정성을 확보한다.
11.2. RAID란?
RAID는 Redundant Array of Inexpensive Disks의 약자로써, 여러 개의 디스크를 배열하여 속도의 증대, 안정성의 증대, 효율성, 가용성의 증대를 하는데 쓰이는 기술이다.
장점
1) 운용 가용성, 데이터 안정성 증대
2) 디스크 용량 증설의 용이성
3) 디스크 I/O 성능 향상
11.3. RAID의 종류와 구성 방식
패리티란?
정보의 홀수 또는 짝수 특성
정보 블록과 연결된 중복 패리티는 오류 후 데이터를 재구축하는데 사용되는 계산 값
11.3.1. RAID 0
RAID 0 에는 Concatenate 방식과 Stripe 방식 두가지가 있다.
1) Concatenate방식

[concat 방식]
-> 두개 이상의 디스크에 데이터를 순차적으로 쓰는 방법 -> 데이터 쌓고 다 차면 다음 디스크에 채우는 방식
장점 : 디스크 기본 공간이 부족할 때 데이터는 보존하며 여분의 디스크를 볼륨에 포함하여 용량 증설이 가능하다.
단점 : RAID 0의 특성상 디스크 중 하나의 디스크라도 장애가 발생하면 복구가 어렵고, 패리티(오류검출기능)를 지원하지 않는다.
용량 : 모든 디스크의 용량을 합친 용량 ex) 300GB disk * 2ea = 600GB
2) Stripe 방식
흔히 RAID 0라고 하면 Stripe 방식을 말하는 것을 생각하면 된다.
-> 두개 이상의 디스크에 데이터를 랜덤하게 쓰는 방법

장점 : 데이터를 사용할 때 I/O를 디스크 수 만큼 분할하여 쓰기 때문에 I/O 속도가 향상 되고I/OController나 I/O board 등 I/O를 담당하는 장치가 별도로 장착된 경우 더 큰 I/O 속도 향상 효과를 볼 수 있다.단점 : Stripe를 구성할 시 기존 데이터는 모두 삭제 되어야 한다. 그 외의 단점은 위의 Concat 방식과 같다.
용량 : 위의 Concat 방식과 같다.
11.3.2. RAID 1 (Mirror)
: Mirror 볼륨 내의 패리티를 사용하지 않고 디스크에 같은 데이터를 중복 기록하여 데이터를 보존하게 되며, 적어도 동일한 용량의 디스크 두 개가 필요하다.

장점 : 볼륨 내 디스크 중 하나의 디스크만 정상이어도 데이터는 보존되어 운영이 가능하기 때문에 가용성이 높고, 복원이 비교적 매우 간단하다.
단점 : 용량이 절반으로 줄고, 쓰기 속도가 조금 느려진다.
용량 : 모든 디스크의 절반의 용량 ex) 300GB *2ea = 300GB //600GB 디스크 크기가 있으면 가용공간은 300GB
반응형11.3.3. RAID 1+0, 0+1
RAID 1+0
RAID 1+0은 특정 프로그램에 대해 mirror을 먼저 수행한 후에 stripe 처리를 하는 방식이라고 할 수 있다.

RAID 0+1
RAID 0+1은 반대로 stripe처리를 먼저 수행한 후에 mirror 처리를 하는 방식이라고 할 수 있다.

mirror 를 먼저하느냐 stripe를 먼저하느냐의 방식의 차이지만 데이터 손실이 생겼을 경우 복구속도에서 둘의 차이는 크다. 위의 그림을 예로들면, 하나의 프로그램을 실행시키기 위해 A,B,C 데이터가 모두 실행이 되어야 한다고 가정하자. 만약 1+0의 경우 Disk1, Disk3 즉 A,B의 데이터에 손실이 생기면 빨간 점선을 기준으로 데이터 A,B,C에 대한 인덱스가 어디에 있는지 알고 있기때문에 빠른 데이터 복구가 가능하다고 볼 수 있다.
0+1에서도 마찬가지로 Disk1,Disk5 즉 A,B가 손실이 생겼다고 가정하자. 복구를 진행해야 돼서 먼저 Disk1,2,3을 살펴보는데 Disk1의 손상이 감지된것을 확인하고 Disk4,5,6을 살펴보게 된다. 하지만 Disk4,5,6도 마찬가지로 Disk5가 손상이 가 있는 상태여서 ABC프로그램을 복구하는 것이 불가능하게 된다.
따라서 1+0은 손실된 데이터만 복구하면 되고 0+1은 데이터 전체를 복구해야 하는 번거로움이 생기기 때문에 실 운영상 RAID 1+0 이 훨씬 유리하다고 볼 수 있다.
11.3.4 RAID 2
: RAID2는 RAID 0처럼 striping 방식이지만 에러 체크와 수정을 할 수 있도록 Hamming code를 사용하고 있는 것이 특징. 하드 디스크에서 ECC(Error Correction Code)를 지원하지 않기 때문에 ECC를 별도의 드라이브에 저장하는 방식으로 처리된다.

하지만 ECC를 위한 드라이브가 손상될 경우는 문제가 발생할 수 있으며 패리티 정보를 하나의 하드 드라이브에 저장하는 RAID 4가 나오면서 거의 사용되지 않는 방식이다.
11.3.5 RAID 3, RAID 4: RAID 3, RAID 4는 RAID 0, RAID 1의 문제점을 보완하기 위한 방식으로 3, 4로 나뉘긴 하지만 RAID 구성 방식은 거의 같다. RAID 3, 4는 기본적으로 RAID 0과 같은 striping 구성을 하고 있어 성능을 보안하고 디스크 용량을 온전히 사용할 수 있게 해주는데 여기에 추가로 에러 체크 및 수정을 위해서 패리티 정보를 별도의 디스크에 따로 저장하게 된다. RAID 3은 데이터를 바이트 단위로 나누어 디스크에 동등하게 분산 기록하며 RAID 4는 데이터를 블록 단위로 나눠 기록하므로 완벽하게 동일하진 않다는 차이가 있다. RAID 3은 드라이브 동기화가 필수적이라 많이 사용되지 않고 RAID 4를 더 많이 쓴다고 보면 된다.

11.3.6 RAID 5
: RAID 5는 RAID 3,4 에서 별도의 패리티 정보 디스크를 사용함으로써 발생하는 문제점을 보완하는 방식으로 패리티 정보를 stripe로 구성된 디스크 내에서 처리하게 만들었다.만약 1개의 하드가 고장 나더라도 남은 하드들을 통해 데이터를 복구할 수 있다는 장점이 있다.

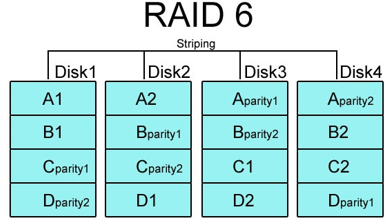
11.3.7 RAID 6
: RAID 6은 RAID 5와 같은 개념이지만 다른 드라이브들 간에 분포되어 있는 2차 패리티 정보를 넣어 2개의 하드에 문제가 생겨도 복구할 수 있게 설계되었으므로 RAID 5보다 더욱 데이터의 안전성을 고려하는 시스템에서 사용됩니다.
출처: https://jwprogramming.tistory.com/24 [개발자를 꿈꾸는 프로그래머]728x90반응형'전공공부 > 운영체제' 카테고리의 다른 글
10. 쓰레싱과 프레임 할당 (0) 2019.12.27 9. 페이지 교체 알고리즘 (2) 2019.12.27 8. 가상 메모리와 요구 페이징 (0) 2019.12.27 7. 메모리 관리 기법(3) - 페이징, 세그멘테이션 (4) 2019.12.26 7. 메모리 관리 기법(2) - 스와핑, 연속 메모리 할당 (1) 2019.12.25